關於 B2Lab
B2 LAB 致力於研發大數據與區塊鏈相結合之金融級應用,提供金融科技即服務(Fintech as a Service: FaaS),協助企業及金融機構導入 B2 Blockchain,將其大量客戶資料和交易訊息上傳至區塊鏈,同時透過大數據分析企業所需情報,進而提升金融科技服務的效率。
B2 Blockchain 是基於 Bitcoin Blockchain 改良而來,專為金融業務需求量身設計。透過區塊鏈的特性,您無須在基礎建設上耗費過多資源,只需將心力專注於您的創新業務即可。
B2 Blockchain 專注於交易即清算、高頻交易、高可靠度的實現,並提供聯盟制交易驗證,您可輕鬆發行數位貨幣、開發電子錢包...等等各式創新金融方案,我們相信 B2 LAB可為您省下可觀的開發成本並帶來無與倫比的效益。
我們的服務
[ 供應鏈金融信評 - B2 Credit Chain ]
-
B2 Credit Chain
我們致力於提供專業的供應鏈金融「信用評等」服務,準確衡量核心廠商與借款供應商、零售商的風險評級。
基於真實、動態的交易訊息,輔以大數據演算法的分析、建模,旨在揭露供應鏈上的真實營運資訊,降低借貸雙方資訊不對稱程度,協助放款進行:幫助提高放款方資訊獲得的完整度,降低作業風險,融資項目涵括整個供應鏈流程,按不同階段協助動態制訂「參考放款成數」、設定「參考融資利率」;幫助供應商提前取得融資、快速彌補資金缺口,提高資金週轉率;幫助零售商取得融資、增加暢銷商品進貨數量,提高資金利用率。
如此提升線下零售行業的整體效率,營造供應鏈上資金運用的良性循環,形成結合多種供應鏈金融服務的零售生態系統,共創供應商、核心廠商、零售商三贏局面。 此外,基於線上業務交易、銷貨往來訊息,建立產業鏈預警模組,改善風險管理。 以上信評資料在去識別化後皆會上傳至區塊鏈做紀錄保存,基於下列區塊鏈的信任機制與不可竄改、可追蹤可溯源的特質,將可充分揭露、以昭公信。
B2 Credit Chain以合作核心廠商之供應鏈上下游往來公司為評等對象,基於線上業務交易、銷貨往來的真實、動態訊息以及供應鏈金融借貸往來之歷程,爰引大數據演算法為眾多考量因子賦予最適權重並進行建模、分析,期能提供更為貼近、反應真實面的信用評等服務。如此,是為「垂直面」的整合。
通過合作核心廠商的增加,我們對其供應鏈上下游往來重疊之公司真實營運資訊的覆蓋性也將愈見完善。針對其與不同核心廠商往來的資料來源,也將分別各自給出源於不同資料來源的風險評級,並透過大數據演算法將多個評級予以加權為最終信用評等。如此,是為「水平面」的整合。
綜合「垂直」、「水平」二維度的風險評級整合,我們相信將能充分揭露供應鏈上的真實營運資訊,降低借貸雙方資訊不對稱程度,協助供應鏈金融服務進行。
-
供應鏈金融承兌平台
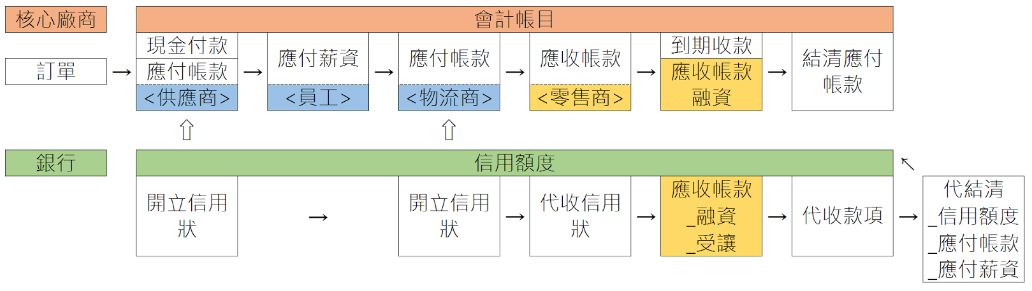
在既有供應鏈體系之交易訊息基礎上,進一步整合金融體系之金流服務,例如:應收、應付帳款處理與融資、對帳銷帳、財務預測、現金流量分析…等。其中融資方面,其項目涵蓋整個供應鏈流程,包括:訂單前融資、訂單融資、驗貨單融資、發票融資以及應收帳款融資。融資條件隨著核心廠商與供應商間不同交易階段的進行而自動調整,當交易越接近立帳(應收帳款)階段,融資成數越高而利率則越低。目的是幫助供應商縮短賬期,快速彌補資金缺口,提高資金週轉率。

資訊電子產業交易支付之週期從立帳(應付帳款)到實際付款約為三至四個月,故供應商若在立帳階段向放款方申請融資,即可以提前三至四個月取得部分銷貨資金。同理,若申請融資之時間點再往前推到發票、驗收單、訂單、甚至預測訂單階段,則取得資金的時間將能大幅提前到六個月以上。
而財務供應鏈,是指在供應鏈的營運週期中,從接獲訂單、生產到交貨的過程裡,所發生一連串用以協助生產的財務需求。
一般而言,財務供應鏈可分為五個階段:- 一、生產期間資金準備—訂單融資。
- 二、交易文件處理—信用狀的開立。
- 三、應收帳款提前兌現—應收帳款融資或交易性質的應收帳款承購。
- 四、帳款支付—支付應付帳款以及應付薪資。
- 五、會計帳目處理。

-
信用評等演算法
Classification is an area of data mining which can be used to train models predicting the categorical class labels of the dependent variable for the cases such as Credit Rating we are interested in. Many classification methods have been proposed in machine learning, statistics and other fields. Most algorithms are memory resident.
-
Logistic Regression
A linear regression model is used to predict a continuous dependent variable. A generalized linear regression model can be applied to model a discrete dependent variable. Logistic regression only for a dichotomous discrete dependent variable is a common type of generalized linear regression model used for the probability estimation of a certain event occurring by fitting data to a logistic function, rather than the value prediction. This event would be more possible to happen if the estimated probability is higher than 0.50, otherwise the output would have a tendency to not happen.
The determination of the dependent variable is based on the estimation of the probability. Suppose that there are two possible discrete values coded as 0 and 1 for the dependent variable: the probability of one discrete value is p and the other one's must be (1-p). Consequently, the final structure of the logistic regression model is the odds log(p/[1-p]) which is often written as logit(p), with the linear regression form.
-
Decision Tree
The structure of a decision tree model is a flowchart-like tree which consists of non-leaf nodes, leaf nodes, branches and the root node. Each non-leaf node denotes a variable with a conditional selection, each branch denotes the outcome of the above selection, and each leaf node denotes the destination of a classification path. There are various decision tree algorithms with various types, such as binary or non-binary trees.
Classification and regression tree (CART) adopts the strategy of divide-and-conquer to solve problems as the same as C4.5. The main differences are represented by the respective splitting criteria, pruning methods and missing value treatments. CART is a type of binary tree, leading to optimally partition discrete variable values of tuples with splitting criterion simplification if their dependent variable is also a binary discrete variable. The splitting criterion, Gini index, is adopted for CART to instead of the general entropy-based criterion for C4.5. The CART authors believe that using Gini index can give consideration to symmetric costs and can calculate it more rapidly than information gain based criteria.
-
Random Forest
Random forest is a type of ensemble model which consists of a set of individual ones. A random forest model consists of a various set of decision trees, depending on the type of problem. The user can decide how many trees in the set s/he wishes. Each tree is learned using “a set of bootstrap tuples” formed by the aggregation of uniform sampling with replacement from the original dataset. Each bootstrap tuple set with the same size as the original dataset is the base for each tree. With these trees, each node is to be a test of decision-making to find the optimal splitting criterion by considering “a randomly selected subset of all independent variables”. The size of each subset should be much smaller than the number of all independent variables. There is no pruning step in the whole process of tree growth.
A random forest model adopts a concept called Bagging (Bootstrap Aggregating) in training tuples selection and introduces randomly selecting in independent variables selection. In other words, random sampling is introduced into the whole process of this algorithm. The selection of Bagging is made with replacement, meaning that there may be more than one appearance of a single tuple in a single bag.
For the problem of numerical prediction, this consists of an averaging mechanism to aggregate the predictions of all trees to obtain the prediction of the ensemble. For the problem of categorical prediction, this consists of a voting mechanism to aggregate the predictions of all trees to obtain the prediction of the ensemble.
-
Bayesian Network
In naïve Bayesian classification, the classifier assumes that all the variables are conditionally independent of one another to simplify the computation. It would be the most accurate classification method if the assumption holds true. However, dependencies can exist between variables for most real problems. Bayesian network can handle this by adopting a directed graphical model of causal relationships in which learning can be performed, representing the joint conditional probability distribution over a set of variables to show different dependencies between different variables. Bayesian network allows conditional independencies to be represented between subsets of variables.
A Bayesian network consists of three components: a directed acyclic graph (DAG), a set of random variables which are represented to be the nodes in the DAG, and a set of conditional probability tables (CPTs). The variables which correspond to the actual attributes may be continuous or discrete. Each arc in the DAG represents a probabilistic dependence between two nodes. If an arc was drawn from one node X to the other node Y, it would mean a representation of the causal knowledge: Y is influenced by X. Note that each node in the graph is conditionally independent of its non-descendant nodes, given its parent nodes. In other words, once we know the outcome of X, then all the other non-parent nodes do not provide any additional information regarding Y.
-
Artificial Neural Network
ANN is a well-known and useful method with various derivative types to solve highly nonlinear problems. We would implement feed-forward neural network because this type is among the most popular. ANN is constructed of multiple computing layers with multiple computing units (neurons) linked to each other. The operation of each neuron is to establish a link between its inputs and output based on a two-step calculation. The process in this link is a linear combination of its inputs in the first step, followed by a nonlinear computation of the above result to obtain its output then fed forward to other neurons in the network. There is an associated weight for each connection of these neurons. ANN consists of network architecture and an appropriate mechanism to look for all connection weights.
Neurons of feed-forward neural network are organized in three different operating layers. The first layer contains the input neurons in which training data are imported into. The final layer contains the output neurons in which the predictions of the network based on the above inputs are exported from. In between, there are one or more hidden layers with multiple operating neurons in the network for learning and adaptation. The kernel of the algorithm is a weight adjustment mechanism, such as the back-propagation method, for obtaining the connection weights and optimizing an appropriate error criterion between the inputs and outputs of the network. This is accomplished by an iterative process of importing training data into the input neurons multiple times and adjusting the connection weights to improve the prediction accuracy of the network, based on obtainment of the prediction values from the output neurons and calculation of the respective prediction error. This iterative process is continued until a certain convergence criterion is satisfied.
-
Support Vector Machine
Support vector machine (SVM) is also a useful method with various derivative types to solve highly nonlinear problem like ANN. SVM has been applied in various research fields and gained increased attention due to its superior prediction accuracy and strong theoretical background. The writings of Vapnik, Cristianini and Shawe-Taylor, and Alex J. Smola and Bernhard Schölkopf are essential documents to make a complete overview of SVM.
Mapping the original data into a new high-dimensional space to make it possible that we can adopt various linear or nonlinear kernel functions to obtain a hyperplane for space separation in classification problems is the basic idea and the initial motivation of SVM. Minimizing the empirical classification error and maximizing the separation margin between tuples of different classes simultaneously is the dual representation of hyperplane separation; consequently, SVM is also named Maximum margin classifier. SVM is an optimization problem solution, which is often implemented by quadratic programming methods and often allowed a small proportion of tuples on the wrong side of the margin to avoid overfitting, each of these would cause a certain cost.
-
[ 區塊鏈清算暨轉帳服務 - Cloud Transfer : TTApp ]
-
目前傳統金融產業正面臨行動金融、互聯網金融等金融科技的衝擊,其中又以數位金融相關的區塊鏈技術為新興顯學,吸引全球政府機關與金融業巨擘相繼大力投資、投入研究。
初始設計上,區塊鏈具有公開透明、互聯互通、共同參與、共享共治的信任機制。實務運用上,區塊鏈具備去中心化、去中介化、不可竄改、可追蹤可溯源的特質。資料維護上,區塊鏈具有可管可控、安全可靠的優勢:可管可控方面,透過治理層面的實作,滿足主管機關、相關機構監管上的需要;透過智能合約的發行,實現貨幣市場與資本市場中諸多金融服務場景的應用。安全可靠方面,在犧牲部分效率的基礎上獲得安全性的極大提升,其可靠程度遠優於傳統資料庫備援機制,經比特幣流通證實可長年穩定運行。更可在其上發行數位貨幣,透過數位憑證乘載實體資產作流通。
技術層面而言,區塊鏈來自以下五項核心技術的綜合與積累:
- 一、隱私性: 注重隱私的密碼學網路支付系統以及各種匿名金融交易支付。
- 二、安全性。
- 三、規模可伸縮性。
- 四、彈性: 智能合約、虛擬機器、監管治理結構、業務邏輯之於實際應用。
- 五、共識演算法:基於算法算力保護的信任機器。
簡言之,金融科技仰賴眾多資訊技術以實現,區塊鏈是主要資訊技術集合做為底層架構的體現。使用B2 Blockchain技術所開發的金融級應用行動APP,可實現國內銀行間跨行轉帳免手續費。
[ 幣富卡曁可攜式行動區塊鏈 - Bift Card: Gift Card on Blockchain ]
使用B2 Blockchain技術所開發的數位資產卡,其上可承載禮券、禮物卡、紅利點數、遊戲點數…等多種資產。